Cómo reorganicé todos mis repos con IA (y de paso mis perfiles de GitHub)

Durante años fui acumulando proyectos como si nada.
Un día tienes un repo para una idea rápida, otro para un experimento, otro para una prueba de concepto que “ya ordenaré cuando tenga tiempo”… y cuando te quieres dar cuenta, tienes repos desperdigados en varias carpetas, remotos duplicados, orígenes apuntando a organizaciones antiguas, y un perfil de GitHub que no cuenta (ni de lejos) lo que haces hoy.
Y si encima, como en mi caso, tienes dos perfiles de GitHub (uno personal y otro profesional), la mezcla es perfecta.
En este artículo quiero contarte todo el proceso que seguí para:
- Centralizar mis proyectos en local.
- Revisar qué repos ya no tenían sentido.
- Decidir qué vive en cada perfil (antoniolg personal y devexpert-io profesional).
- Migrar repos y ajustar
originsin perder nada. - Dejar en local solo lo activo (y que el resto viva en GitHub).
- Y, al final, poner bonitos y coherentes los perfiles de GitHub.
Pero, sobre todo, quiero enseñarte el enfoque: porque la idea no es que copies mis repos, sino que copies un método que te sirva para ordenar los tuyos.
El problema real (no era el código)
Cuando hablamos de IA en programación, la conversación suele ir por “qué bien escribe código”.
Pero en esta historia, lo más valioso no fue que la IA programara nada.
Lo importante fue usarla como asistente para una tarea compleja, tediosa y con riesgo:
- Mucha información dispersa.
- Decisiones manuales (esto vale, esto no, esto va aquí…).
- Riesgo de borrar algo que sí importaba.
- Y la típica sensación de “no sé ni por dónde empezar”.
La IA fue mi “PM obsesivo” y mi “asistente de operaciones”: me ayudó a hacer inventario, detectar inconsistencias, proponer un plan, y llevar un seguimiento de decisiones sin volverme loco.
El objetivo (muy concreto)
Antes de tocar nada, fijé un objetivo simple y medible:
- Centralizar todo en
/Users/antonio/Projects. - Revisar qué proyectos ya no servían (archivar primero, borrar solo si era seguro).
- Migrar lo que correspondiese entre perfiles y actualizar
origin. - Actualizar ambos perfiles de GitHub para reflejar lo activo.
- Dejar en local solo lo que estuviera usando.
La clave estuvo en esa frase: “sin perder nada importante”.
Así que el proceso tenía que ser incremental, con checkpoints, y con una regla de oro:
No se borra nada “a ciegas”. Primero inventario, luego decisiones, luego ejecución.
Paso 1: inventario local (antes de opinar)
Lo primero fue responder a una pregunta que parece tonta, pero no lo es:
¿Cuántos repos tengo, y dónde están?
En mi caso estaban repartidos en varias carpetas (por ejemplo AndroidStudioProjects, IdeaProjects, etc.). La IA me ayudó a recorrerlas y generar un inventario con señales útiles, por repo:
- Si tenía
origino no. - A qué owner apuntaba (personal, org, terceros, orgs antiguas…).
- Si estaba “dirty” (cambios sin commitear).
- Si iba “ahead/behind” respecto al remoto.
- Si tenía stashes.
El resultado fue bastante revelador:
- 106 repos locales.
- 16 sin
origin(solo local, sin remoto). - 56 con cambios locales (dirty).
- Algunos con commits sin push.
- Y varios apuntando a owners distintos a mis dos perfiles.
Ese inventario, por sí solo, ya te cambia la perspectiva: deja de ser “sensación de caos” y pasa a ser una lista finita de cosas que resolver.
Paso 2: inventario remoto (los dos perfiles)
El siguiente paso fue hacer lo mismo, pero en remoto.
Para esto tiré de la CLI de GitHub (gh), porque te permite listar repos y sacar datos rápido sin pelearte con la UI.
Aquí la pregunta era:
¿Qué repos existen en GitHub en antoniolg y en devexpert-io, y cuáles no tienen equivalente local?
El inventario remoto fue:
antoniolg: 98 reposdevexpert-io: 48 repos
Y lo importante vino después: cruzar esa información con la local.
Paso 3: reconciliación (cruzar datos y encontrar “problemas”)
Aquí es donde la IA brilla, porque es una tarea perfecta para ella:
- Mucho dato.
- Reglas claras.
- Salida tabular para tomar decisiones.
Lo que buscamos con el cruce es detectar, por ejemplo:
- Repos solo-local (sin
origin). - Repos locales con
origina terceros. - Repos que deberían existir en remoto pero no aparecen.
- Repos que existen en remoto pero no están en local (y decidir si merece la pena clonarlos o ignorarlos).
Una de las cosas más útiles fue convertir todo esto en “listas accionables” (tipo: “sin origin”, “otros owners”, “missing remote”…), para revisar por lotes en vez de ir a ciegas.
Paso 4: el método de decisiones (sin una web, por favor)
En algún momento me planteé: “¿hago una herramienta web para esto?”.
Y la respuesta fue: no hace falta.
Para este tipo de tareas, lo más eficiente es algo muy simple:
- Un inventario estructurado (TSV/CSV).
- Un flujo de decisiones.
- Y un registro de lo que vas haciendo para no repetir pasos.
La IA me propuso y montó un sistema de “decision sheets” donde, repo a repo, íbamos anotando:
- Acción (mantener, archivar, migrar, borrar local…).
- Destino (perfil personal u org).
- Notas (qué es, por qué se queda, qué depende de qué…).
Esto parece poca cosa, pero es lo que evita el desastre típico de:
“Creo que ya migré esto… espera, no, era el otro…”
Por supuesto, estos archivos no los toqué yo manualmente, era el registro para que la IA supiera por dónde íbamos.
Paso 5: reglas simples para un caos complejo
Aunque había decisiones manuales, había algunas reglas que simplificaban muchísimo.
Por ejemplo, yo tenía repos antiguos apuntando a una organización con nombre viejo (DevExperto). La regla fue:
- Todo lo que sea
DevExperto/*debe vivir endevexpert-io/*.
No significa que hubiera que hacerlo automático sin mirar, pero sí que te da una dirección clara, y la IA puede ayudarte a detectar todos los casos.
Paso 6: ejecución (mover, migrar, limpiar)
Aquí es donde hay que ser cuidadoso: lo importante no es “hacerlo rápido”, sino hacerlo con seguridad.
En mi caso, el objetivo final local era muy claro: todo bajo /Users/antonio/Projects.
Y el objetivo final operativo era este:
- Dejar solo repos activos en local.
- Asegurar que todo lo importante está en remoto.
- Migrar repos al owner correcto (personal vs org).
- Ajustar
originpara que el repo “sepa” dónde vive.
Al final, el resultado fue:
- 12 repos activos en
devexpert-io - 18 repos activos en
antoniolg
El resto, o bien quedó archivado/remoto, o se eliminó en local, o se dejó como histórico (dependiendo del caso).
Paso 7: perfiles de GitHub (la parte que de verdad se ve)
Aquí viene una realidad incómoda:
Puedes tener tus repos perfectos… y aun así, tu perfil de GitHub puede parecer abandonado.
Así que, una vez que el terreno estuvo más o menos limpio, pasé a lo visible:
Perfil personal (antoniolg)
El objetivo era que reflejara lo que hago hoy:
- Proyectos “Current”.
- Enlaces con badges (más limpios que una lista de links).
- Secciones que aporten contexto (por ejemplo “Milestones”).
- Un pequeño “callout” a devexpert.io.
- Actividad de GitHub en un sitio lógico.
- Y, ya que estamos, integrar cosas como artículos recientes o charlas (que quien llega tenga 4-5 cosas para saber más qué hago).
Si te interesa, puedes ver el repo del README del perfil aquí: antoniolg/antoniolg.
Perfil de la organización (devexpert-io)
Aquí había un detalle interesante: la org ni siquiera tenía un repo de perfil.
Montamos lo básico:
- Repo
devexpert-io/.github profile/README.md- Listado de repos destacados
- Descripciones “humanas”
- Badges de redes
- Secciones extra (artículos recientes, charlas, “sobre Antonio” para dar contexto al creador)
Y, a partir de ahí, iterar.
No era “hacer el README perfecto”, era hacerlo vivo: algo que puedes mejorar en 10 minutos cuando cambie el foco.
Un pantallazo (para que te hagas una idea)
Así quedó el perfil personal tras esta iteración:
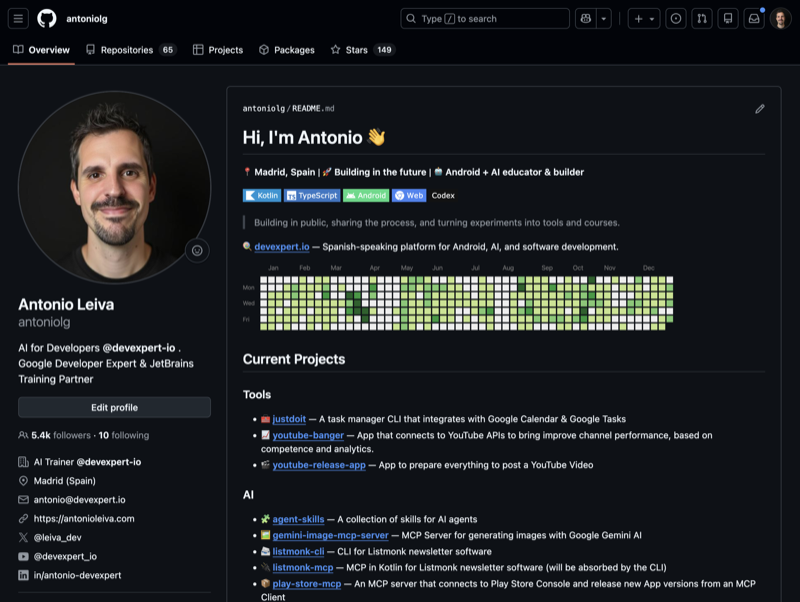
La idea clave: la IA como asistente, no solo como generador de código
Si te tienes que quedar con una sola idea, que sea esta:
La IA no sirve solo para escribir funciones o refactorizar.
También es tremendamente útil como asistente para:
- Organizar información.
- Crear inventarios.
- Detectar inconsistencias.
- Proponer un plan de acción.
- Convertir “algo grande” en una lista de pasos pequeños.
- Mantener un registro de decisiones.
Y eso, en el día a día, es oro.
Porque la mayoría de tareas que nos frenan no son “difíciles a nivel técnico”. Son difíciles por cantidad, por dispersión, o por falta de claridad.
Si quieres hacerlo tú (sin sufrir)
Mi recomendación, si te planteas algo parecido:
- Haz inventario local y remoto.
- Cruza ambos mundos y saca “listas accionables”.
- Decide con calma (archivar antes que borrar).
- Ejecuta con cuidado y con checkpoints.
- Y, al final, actualiza tus perfiles para que cuenten tu historia actual.
Si tú también estás en ese punto de “tengo que ordenar esto de una vez”… hazte un favor: no lo hagas a mano y a ciegas. Usa la IA como asistente.
Duelo de LLMs: Gemini 3 Flash vs Opus 4.5 vs GPT-5.2-Codex vs GLM-4.7
Cerrando el círculo de la IA en Desarrollo de Software