Duelo de LLMs: Gemini 3 Flash vs Opus 4.5 vs GPT-5.2-Codex vs GLM-4.7

¿Por qué no me sirves otro LLM?
La locura de modelos de estas últimas semanas, todos diciendo en los benchmarks que superan al anterior, debo reconocer que me ha generado un poquito de curiosidad y ansiedad a partes iguales.
¿Pero podemos hoy en día fiarnos de los benchmarks? Yo personalmente creo que no.
Primero porque los benchmarks son siempre escenarios muy concretos que no reflejan el uso real que le vamos a dar a un modelo. Y segundo, porque cada uno nos adaptamos mejor a unos modelos que a otros en función de nuestra forma de trabajar.
Así que he decidido hacer un pequeño duelo entre los cuatro modelos que más ruido han hecho en las últimas semanas: Gemini 3 Flash, Opus 4.5, GPT-5.2-Codex y GLM-4.7.
La base de pruebas
Durante varios meses, llevo trabajando en una App que me ayuda con mi gestión de redes sociales.
No sé si algún día verá la luz, porque la estoy adaptando mucho a mis necesidades, pero estoy muy orgulloso del resultado.
Un caso muy concreto que tengo es que publico en redes en distintos idiomas, y la App me permite definir en qué idioma publico en cada perfil social.
Algo que he añadido también recientemente es la posibilidad de generar una publicación a partir de un link, extrayendo la imagen principal, y poniendo el link en el primer comentario (para evitar penalizaciones de los algoritmos).
También tengo un generador de imágenes mediante IA maravilloso, donde puedes definir tu propio avatar para incluirte en las imágenes, e incluso recientemente añadí la posibilidad de “traducir imágenes”.
Muy guay todo, y me permite poner en práctica muchas cosas de las que luego les cuento a mis alumnos en AI Expert
El reto
Hace unos días se publicó otro modelo, Qwen Image Layered, que permite separar una imagen por capas.
Esto es extremadamente útil para hacer thumbnails para YouTube:
- Creas una o varias imágenes con Nano Banana Pro
- Separas las capas con Qwen Image Layered
- Te quedas con lo que quieras, adaptas el tamaño, añades elementos extra
- Si quieres, incluso le das un último toque con Nano Banana Pro
El caso es que llevaba tiempo queriendo montar un editor de imágenes, para ayudarme con los thumbnails de YouTube, y este modelo me dio el impulso que me faltaba.
Así que pensé que era un caso de uso perfecto para probar los cuatro modelos.
Las instrucciones
Mi idea no era solo probar si el modelo generaba el código, son cómo planificaba la tarea y cuánto investigaba antes de ponerse a trabajar.
Es por ello que le di las siguientes instrucciones:
Quiero añadir una nueva funcionalidad: un editor de imágenes, que estará en una nueva página
dentro de esta App. La idea es aprovechar toda la funcionalidad de generación de imágenes que ya existe, pero añadirle varios puntos:
1. Poder añadir nuevos elementos subidos desde el ordenador
2. Trabajar con capas. Para ello se usará el modelo qwen-image-layered desde fal.ai, que
descompone la imagen que genere el modelo de generación de imágenes en capas. Aquí tienes
la documentación: <la omito por brevedad>
3. Un chat donde se le pueden pedir cambios a la imagen
4. La descomposición en capas no se hará hasta que el usuario no esté contento con la
imagen y pulse un botón
Pregúntame las dudas que tengas antes de empezar.El secreto estaba en esta última frase:
Pregúntame las dudas que tengas antes de empezar.
Quería asegurarme de que me preguntaban todo lo necesario antes de ponerse a trabajar.
Los modelos
Opus 4.5 es para casi todo el mundo el modelo a batir. Pero yo personalmente tengo muy buena experiencia con la familia Codex, y especialmente este GPT-5.2-Codex me está encantando.
Pero hace unos días Google anunció Gemini 3 Flash, y algunos benchmarks decían que era el mejor modelo de todos.
Finalmente, ayer mismo se anunció GLM-4.7, que también prometía mucho.
Así que estos cuatro modelos fueron los que utilicé para el duelo.
¿El ganador? Sigue leyendo.
Gemini 3 Flash

Gemini 3 Flash es probablemente el modelo más sorprendente de este año.
Baratísimo, rapidísimo, y con unas capacidades que en algunos benchmarks superan al modelo Pro.
¿Tiene sentido? Parece que no, pero por lo visto Google ha usado estrategias de aprendizaje por refuerzo que en la versión Pro no les dio tiempo a implementar. Y se nota.
Desde 2.5 Pro, siempre he usado Gemini para todo menos para programar. Y con 3 Flash es la primera vez que confío en un modelo tan rápido. Siempre me da respeto que por usar el modelo “malo” los resultados no sean suficientemente buenos. Pero con 3 Flash no siento esto.
¿Para programar? Mis pruebas han sido erráticas. Es rapidísimo, y capaz de generar mucho código de una vez.
Pero le pasa lo que a muchos modelos de este tipo: es muy impaciente. Quiere generar el código cuanto antes, y muchas veces toma atajos que salen caros.
Para trabajar con este modelo, usé Gemini-CLI.
En este caso, las preguntas que me hizo fueron bastante básicas, y no extrajo mucha información. Yo caí en ese momento en que me gustaría integrarlo con el composer de publicaciones, pudiendo guardar las imágenes generadas para luego reutilizarlas desde el Composer. Cosa que con otros se me olvidó.
¿El resultado?
-
Interfaz: 3/5 -> Una UI básica, sin mucha gracia, pero funcional.
-
Funcionalidad: 3/5 -> Cumplió con lo que le pedí, pero sin más. Estaba lejos de ser un editor listo para publicar.
-
Robustez: 2/5 -> La mayoría de las funcionalidades no funcionaban como se esperaría. El editor no ajustaba bien las capas, el espacio era enorme y no se sabía bien dónde empezaba y acababa el diseño.
-
Proactividad y Planificación: 2/5 -> No hizo muchas preguntas, y se lanzó a generar el código sin más. Se notaba que quería acabar rápido.
TOTAL: 10/20
Una cosa que hizo muy bien fue integrarse con el composer, cosa que otros no hicieron. Bien porque no se lo pedí, bien porque no fueron capaces. Luego te cuento.
Eso sí, fue con creces el más rápido de todos. Es impresionante lo que hace para el tiempo que tarda.
GPT-5.2-Codex High
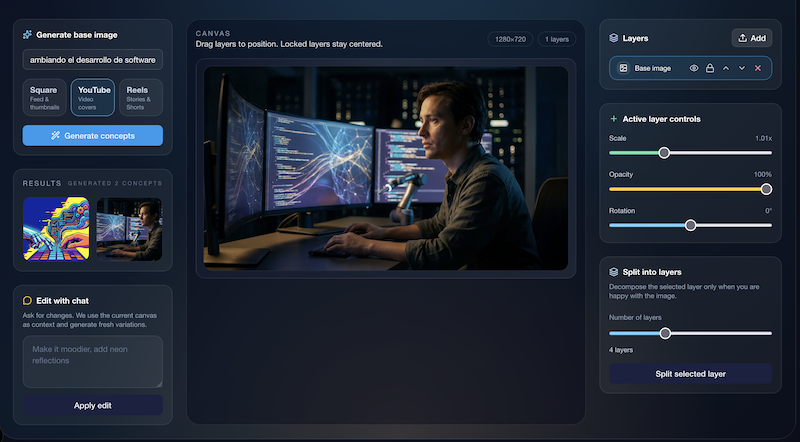
No voy a negar mi debilidad por los modelos Codex. Son mi día a día para programar, y los resultados que obtengo son siempre muy buenos.
La semana pasada publiqué un vídeo sobre GPT-5.2, pero ese mismo día salió la versión Codex, entrenada y optimizada para trabajar con el CLI de OpenAI. Y se nota.
Usé Codex-CLI, y High como nivel de razonamiento.
Las preguntas fueron más precisas. En este caso sí te las puedo poner:
• Perfecto. Antes de tocar código necesito aclarar algunos puntos:
- Ruta y navegación: ¿dónde quieres la nueva página del editor (URL y desde qué menú/CTA se
accede)?
- Flujo exacto: ¿la generación inicial de imagen es la misma que ya existe hoy (mismo modelo/
endpoint) y luego se entra al editor, o el editor incluye la generación dentro de la misma
pantalla?
- Chat de cambios: ¿qué modelo/endpoint se usa para aplicar cambios desde el chat (el mismo de
generación existente o uno nuevo)? ¿Y el chat debe mantener historial por sesión?
- Subidas desde ordenador: ¿es para añadir nuevas capas/elementos encima de la imagen (stickers)
o para reemplazar la imagen base? ¿Qué formatos y tamaño máximo?
- Capas: cuando usemos qwen-image-layered, ¿cómo quieres mostrar las capas (lista con
visibilidad/orden, miniaturas, etc.)? ¿Se podrán reordenar, ocultar o combinar?
- “No descomponer hasta que el usuario esté contento”: ¿qué significa exactamente “contento”?
¿Solo al pulsar un botón “Separar en capas” o hay otro criterio?
- Persistencia: ¿hay que guardar el estado del editor en DB (proyecto/imagen, capas, chat) o
puede ser solo estado en cliente?
- Specs: ¿hay specs en specs/ que debamos actualizar o crear nuevas? ¿Quieres que prepare un
spec/plan antes de implementar?
Cuando me confirmes esto, empiezo. También, por ser UI nueva, usaré DevTools MCP para revisar
consola y comportamiento.El resultado me dejó literalmente con la boca abierta. Más que una funcionalidad nueva, parecía un producto aparte.
Para lo bueno, y para lo malo.
- Interfaz: 4/5 -> Una UI muy cuidada, con detalles muy profesionales y avanzados. El único problema es que se fue demasiado del estilo visual de la App, y no encajaba bien.
- Funcionalidad: 5/5 -> Cumplía con todo lo que le pedí, e incluso más. Tenía funcionalidades que no esperaba para gestionar las capas.
- Robustez: 5/5 -> Creo que fue el único en el que todo lo que implementó funcionaba a la primera.
- Proactividad y Planificación: 4/5 -> Las preguntas que hizo fueron buenas, pero no increíbles. Hubo otro modelo que lo hizo mejor.
En este caso no le pedí que se integrara con el composer, lo que es una pena, porque me habría gustado ver si lo resolvía bien.
TOTAL: 18/20
Este modelo no deja de impresionarme, sinceramente.
GLM-4.7
GLM-4.7 es el modelo que menos conocía de los cuatro. De hecho nunca había usado ningún modelo de la familia GLM.
Pero la gente habla muy bien de ellos, y de este dicen que está muy cerca de Opus 4.5, pero a una fracción del coste.
De hecho, es el más barato de los 4. Incluso más que Gemini 3 Flash, lo cual es sorprendente.
En este caso usé OpenCode. Pagué por usarlo a través de OpenRouter, y luego me di cuenta de que ahora mismo está gratis en OpenCode 🤦♂️🤦♂️
En cualquier caso, el coste de toda la feature fue poco más de 1$.
Las preguntas que me hizo fueron estas:
Entiendo el contexto. Antes de empezar, necesito algunas aclaraciones:
1. API de fal.ai: ¿Tienes ya una FAL_KEY configurada en tu .env o necesitamos añadirla?
2. Almacenamiento de capas/proyectos de edición: ¿Quieres crear un nuevo modelo en Prisma para guardar los proyectos de imágenes editadas con sus capas, o simplemente mantener todo en memoria/sesión?
3. Ubicación de la página: ¿Qué ruta prefieres para el editor de imágenes? Por ejemplo: (dashboard)/image-editor o (dashboard)/editor-de-imagenes
4. Flujo final después de editar: ¿Qué debería poder hacer el usuario con la imagen editada? ¿Guardarla para usar en posts, exportar como archivo, ambas?
5. Chat de edición de imagen: El chat para pedir cambios a la imagen ¿debe usar el mismo modelo de generación de imágenes (Gemini) o uno diferente optimizado para edición?
6. Controles de capas: Además de ver las capas, ¿qué controles necesitas? (visibilidad, reordenar, fusionar, etc.)
7. Subida de archivos: ¿Hay límites de tamaño o tipo de archivos para los elementos subidos desde el ordenador?En este caso las preguntas no fueron malas, pero algunas me parecieron un poco irrelevantes. Fue especialmente interesante la 4, que me dio pie a explicarle que quería integrarlo con el composer.
El resultado fue, con diferencia, el peor de todos. No me esperaba esto después de leer que lo comparaban con Opus 4.5.
- Interfaz: 2/5 -> Una UI muy básica, sin apenas estilo, y con una usabilidad bastante pobre.
- Funcionalidad: 2/5 -> Todo estaba a medio cocer. Por ejemplo el canvas no permitía mover las capas, y poco se podía hacer con ellas. Y a pesar de que le pedí integración con el composer, no lo hizo.
- Robustez: 3/5 -> Fallar no fallaba, no había crashes evidentes, pero casi nada hacía lo que se esperaba.
- Proactividad y Planificación: 3/5 -> Las preguntas fueron correctas, pero no especialmente profundas.
TOTAL: 10/20
Opus 4.5
Me lo estuve pensando seriamente por el coste, pero al final decidí usar Opus 4.5 a través de OpenCode y OpenRouter.
Nunca pensé qué me dejaría más de 10$ en un único prompt 😅, pero quería ver si realmente es tan bueno.
Disclaimer aquí de que es posible que con Claude Code funcione mejor.
Aún así, hay que reconocer que, en este caso, su fama está más que justificada.
Las preguntas fueron sin lugar a dudas las mejores de todos los modelos:
Interesante funcionalidad. Antes de empezar, tengo varias preguntas para asegurarme de entender bien el alcance:
Preguntas sobre la funcionalidad
1. Flujo general
- ¿El flujo sería: Generar imagen → Chat para refinar → Descomponer en capas → Editar capas?
- ¿O el usuario puede empezar subiendo una imagen propia directamente?
2. Editor de capas
- Una vez descompuesta la imagen en capas, ¿qué operaciones debe poder hacer el usuario con cada capa?
- ¿Mover/reposicionar?
- ¿Escalar/rotar?
- ¿Cambiar opacidad?
- ¿Eliminar capas?
- ¿Reordenar capas (z-index)?
- ¿Aplicar filtros?
3. Elementos subidos
- Cuando dices "añadir nuevos elementos subidos desde el ordenador", ¿estos se añaden como nuevas capas independientes sobre la imagen generada?
- ¿Hay límite de tamaño/formato para las imágenes subidas?
4. Chat para cambios
- ¿Este chat debe poder modificar la imagen base (regenerarla con nuevos prompts)?
- ¿O también debe poder modificar capas individuales una vez descompuesta?
- ¿Usamos el mismo sistema de AI que ya existe en el proyecto?
5. Persistencia
- ¿Hay que guardar los proyectos del editor en base de datos?
- ¿El usuario debe poder volver a un proyecto anterior?
6. Exportación
- ¿El resultado final se exporta como imagen plana (merged)?
- ¿O también como proyecto con capas separadas (tipo PSD)?
7. Ubicación en la app
- ¿La nueva página estaría dentro del dashboard (/editor o similar)?
- ¿Accesible desde la navegación principal?
8. Integración con el composer
- ¿Las imágenes editadas se pueden usar directamente en el composer de posts?Preguntó literalmente todo lo relevante para implementarla bien. El resultado fue que a nivel de integración, fue la que mejor lo hizo.
- Interfaz: 5/5 -> Personalmente es la que más me gustó. No era la más llamativa, pero integró exactamente la misma interfaz que ya estaba usando para imágenes en el composer. Reutilizó componentes y estilos. Por lo que de primeras incluía muchas funciones que otros no. El estilo minimalista me gustó mucho.
- Funcionalidad: 4/5 -> Intentó generar un sistema por pasos que no terminaba de funcionar del todo bien. La idea era buena, pero la ejecución no tanto. El sistema de capas estaba muy bien, pero le faltaban algunas cosas que me parecen útiles, como elegir en cuantas capas descomponer la imagen.
- Robustez: 3/5 -> Aquí es donde me sorprendió para mal. Muchas cosas no funcionaba como cabría esperar. Las capas no se podían mover bien, y la opción de usar la imagen en el composer directamente no funcionaba. Le faltaba pulir muchos detalles.
- Proactividad y Planificación: 5/5 -> Sin duda las mejores preguntas de todas. Cubrió todos los puntos relevantes, y me hizo pensar en cosas que no había considerado.
TOTAL: 17/20
Conclusiones
Está claro que los dos modelos que indiscutiblemente están a otro nivel en desarrollo son GPT-5.2-Codex y Opus 4.5.
Ambos hicieron un trabajo muy bueno, pero la capacidad de Codex para afinar la funcionalidad y crear un producto casi terminado me dejó impresionado. Es lo que más me gusta de este modelo, y aquí volvió a demostrarlo.
Opus 4.5 hizo un trabajo excelente en planificación y en integración con el resto de la App, pero le faltó pulir muchos detalles para que la funcionalidad fuera realmente usable.
Los otros dos modelos, Gemini 3 Flash y GLM-4.7, son mucho más baratos, pero también los resultados son claramente inferiores. Aún así, Gemini 3 Flash me gusta mucho porque se puede iterar muy rápido y sus resultados son muy buenos para tareas pequeñas.
Lo que es indiscutible es que la evolución este año de los LLMs para desarrollo ha sido espectacular.
Lo que a principios de año era una herramienta de apoyo, ahora mismo es capaz de hacer trabajos complejos casi de forma autónoma.
No sé qué nos deparará 2026, pero estoy seguro de que será un año apasionante.
Duelo de LLMs: Gemini 3 Flash vs Opus 4.5 vs GPT-5.2-Codex vs GLM-4.7
Cerrando el círculo de la IA en Desarrollo de Software